「robots.txtってどういう効果がある?」
「設定するとSEOにどんな影響があるの?」
「robots.txtの正しい書き方がわからない…」
robots.txtというと、書き方や配置場所といったテンプレ的な情報ばかり散見されます。もっとも安全に設定するには、自社サイトのディレクトリ構造を深く理解することがかかせません。
 福田卓馬
福田卓馬サンプルのコードの真似をするだけでは、重要ページまでクロール不可になり、検索結果から消えてしまうリスクがあります。
本記事では、200社以上のSEO支援実績を持つEXTAGE株式会社が、robots.txtの意味・書き方・確認方法・よくある失敗までを体系的に解説します。
- robots.txtの意味とSEO効果
- 旧テスター廃止後の確認方法
- 正しい書き方とAI拒否設定
- WordPress設定とよくある失敗
最後まで読めば、事故をふせぎながら、余計なページのクロールを止めてサイトの評価を高められます。とくに、ECサイトなどの大規模サイトを運営している方は、必ず理解しておきましょう。
本記事の執筆者

福田 卓馬
EXTAGE株式会社 代表取締役社長
SEO歴10年。上場企業を含む200社以上のSEO・Webマーケティング支援を実施。KADOKAWA社より『文章で金持ちになる教科書』『Webライターが5億円稼ぐ仕組み』を出版。
>>詳しいプロフィールはこちらrobots.txtの前に、サイト全体の設計を見直したい方はこちらの資料もあわせてご活用ください。
\60P超えのコンテンツを無料配布!/

Webサイト運営に悩む中小企業が、検索順位を上げるためのポイントをまとめたコンテンツを無料配布!コンテンツ改善のポイントから、SEOにおける内部、外部対策、さらに最新のAI検索に対応した改善方法まで網羅しています。ぜひ無料で受け取って活用してください。
robots.txtとは
robots.txtとは、Googleなどの検索エンジンのクローラーに対し、サイト内のどのページをクロールしてよいか/クロールしてほしくないかを伝えるテキストファイルです。
Webサイトを自動巡回してページ情報を収集するプログラム。
サイトのルート直下(https://example.com/robots.txt)に1枚だけ設置し、Disallow(拒否)やAllow(許可)といった指示を記述します。
福田卓馬ページが大量にあるECサイトや、大規模サイトほどrobots.txtが重要です。
クロール最適化などのSEO効果がある
robots.txtを設定すると得られるSEO効果は、クロールの節約です。
Googleは、Webサイトをクロール(巡回)して評価します。ただし、サイトの規模によって巡回数に上限があります。余計なページがクロールされると、重要なページを評価しきれないケースがあるのです。
たとえば、絞り込みや検索の結果ページなど「内容が同じでインデックスする意味がないページ」は、そもそもクロールされないよう指示すべきです。
福田卓馬EXTAGE支援先の大手カタログギフトECサイトでは、不要ページが最大29万ページに達した事例があります。
Web制作会社でも、robots.txtの仕様を十分に理解していないところは少なくありません。サイト立ち上げ後、まったくrobots.txtを確認していないと、本来集められるはずのアクセスを取り逃がしているかもしれません。
noindexと併用してはいけない
robots.txtとnoindexは、併用しないようにしましょう。
それぞれの違いとして、robots.txtは「クロール自体を止める」のに対し、noindexは「クロールはできるが検索結果には表示しない」指示です。
| 項目 | robots.txt | noindex |
|---|---|---|
| 対象 | クロール制御 | インデックス制御 |
| 指示内容 | クロール自体をブロック | 検索結果に表示しない |
| Googleの認識 | クローラーが読み取る前にブロック | クローラーがページ訪問後に読み取り |
| 検索結果への影響 | インデックスが残る可能性がある | インデックスが除外される |
noindexを付与したページにクロールブロックをかけると、タグ自体を読み取れません。結果的に検索結果から消えなくなります。
検索結果に表示したくないページはnoindexで制御しましょう。robots.txtはクロール自体を止めたい重複・大量生成ページに使うのが適切です。
noindexとnofollowの細かい違いまで知りたい方は「noindex・nofollowとは?SEOでの違いと正しい使い分け」でくわしく解説しています。あわせて参考にしてみてください。

robots.txt設定前に|自社サイトのディレクトリ構造の確認が重要
robots.txtでもっとも重要なのは、書き方のテンプレ暗記ではなく、自社サイトのディレクトリ構造の把握です。一般的にはサンプルコードの流用が広まっていますが、実際はサイトごとに構造が違うため、構造理解なしに設定すると重要ページを消し飛ばすリスクがあります。
ファイルやページをツリー状に整理するしくみのこと。
Webサイトによってディレクトリ構造は異なるので、杓子定規にrobots.txtを設定するのは不適切です。必要なページのクロールをブロックしたり、不要なクロールを見逃したりするリスクがあります。
福田卓馬スプレッドシートに各ページのURLを書き出し、制御対象をリストアップしましょう。
| カテゴリ | 具体例 | 処理 |
|---|---|---|
| 主要コンテンツ | /top/blog(/column)/category/ | 許可する |
| 会員エリア | /wp-admin//login | 拒否する |
| テスト環境 | stg.example.com/test | 拒否する |
| パラメータ | /?sort=/?color= | 拒否する |
| 検索結果ページ | /tag/?s= | 拒否する |
| CMS内部ファイル | /wp-includes//wp-content/plugins/ | 拒否する |
実際のディレクトリ構造をチェックするには、Webサイトの各種ページを開き、それぞれのURLがどんな構造になっているかを目視でチェック・メモするのが確実です。
robots.txtの4つの確認方法
robots.txtの確認方法は、目視・Search Consoleレポート・URL検査・外部Validatorの4つを用途別に使い分けるのが正解です。全体チェックは目視、ページ単位はURL検査、公開前の構文検証は外部ツールと役割を分けると事故を最小化できます。
| 確認方法 | 主な用途 |
|---|---|
| ブラウザで目視確認 | 公開中のrobots.txt全体を即確認 |
Googleサーチコンソールのrobots.txtレポート | Googleが実際に読み取った履歴・エラー確認 |
| URL検査ツール | 特定URLがブロックされているかを個別確認 |
| validator/checkerなどの無料ツール | 公開前の構文ミス・Bot別挙動のシミュレーション |
それぞれくわしく解説します。
ブラウザで目視確認
robots.txtを確認するには、ブラウザで目視するのがもっとも手軽です。
WebサイトのトップページのURLに対し、末尾に/robots.txtをつけてアクセスすると、robots.txtが表示されます。自社のURLがexample.comならhttps://example.com/robots.txtです。
表示された内容を読むときは、次の順で目を通してください。
- 冒頭の
User-agentが意図どおりか(*か特定クローラーか) Disallow:の行にブロックすべきでないパスが入っていないかDisallow: /(サイト全体拒否)が残っていないかSitemap:行でXMLサイトマップの場所が正しく通知されているか
福田卓馬目視だけでもDisallow: /のような致命的ミスは検知できます。
Search Consoleをまだ導入していない方は、次の確認方法に進む前に「サーチコンソールの設定方法|初心者向けに登録から使い方まで解説」を参考に、先に基本設定を整えておいてください。

Googleサーチコンソールのrobots.txtレポート
Googleサーチコンソールのrobots.txtレポートでは、現在の設定状況だけでなくバージョンや取得日、エラー・警告の件数まで調べられます。
とくに、過去のバージョンは最大30日間保存されるので、いつ誰がどこを変更したかをさかのぼって確認できます。
| 確認できる項目 | 用途 |
|---|---|
| 最新取得日時 | 変更が反映されたかの確認 |
| 取得ステータス(取得済み/エラー) | 読み取り失敗の検知 |
| エラー/警告の行番号 | 構文ミスの原因特定 |
| 過去のバージョン | 誤編集時のロールバック元を参照 |
いきなりサイトが検索結果から消えてしまったときは、レポートで更新履歴が残っていないか確認するのが有効です。
URL検査ツール
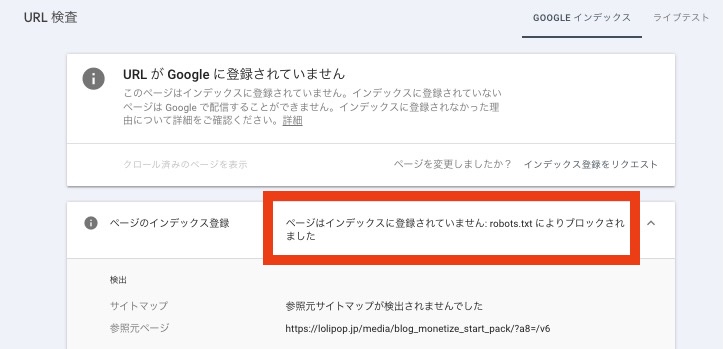
GoogleサーチコンソールのURL検査ツールは、ページ単位で「robots.txtにブロックされていないか」を確認したいときに用います。
Googleサーチコンソールの画面上部の検索窓に、検査したいページのURLを入力するだけで、インデックス・クロール状況を把握できます。
| 表示 | 状態 |
|---|---|
| ページはインデックスに登録されています | robots.txtが効いておらず、検索結果にも表示される |
| ページはインデックスに登録されていません | robots.txtは効いていないが、検索結果には表示されない |
| robots.txtによる除外 | robots.txtが効いている |
robots.txtでブロックされているときは、インデックス登録状況の部分に表示される仕様です。
validator/checkerなどの無料ツール
公開前に、robots.txtの構文が間違っていないかチェックしたいときは、validatorやrobots.txt許可チェッカーなどの無料ツールが便利です。
ツールごとの特徴を整理しました。
| ツール名 | 特徴 |
|---|---|
| TechnicalSEO.com robots.txt Validator | 任意のURLと任意のBotで挙動をテスト |
| robots.txt許可チェッカー | 記述とURLを入力するとクロールの可否を確認できる |
もともとはGoogleサーチコンソールのrobots.txtで精査できましたが、現在は使えないので、外部ツールを活用しましょう。
福田卓馬外部ツールは公開前の事前検証用と割り切って使うのがおすすめです。
本番反映後は、必ずGoogleサーチコンソールのrobots.txtレポートで最終確認してください。
robots.txtの書き方
robots.txtの書き方は「User-agent」「Disallow」「Allow」「Sitemap」の4つだけ、かんたんに理解しておけば問題ありません。
記述ルールが明確かつ端的なので、一度フォーマットさえ覚えてしまえば、専門知識がなくてもかんたんに記述できます。
| ディレクティブ | 役割 |
|---|---|
User-agent | 対象クローラーを指定 |
Disallow | クロールを拒否するパスを指定 |
Allow | Disallow配下で例外的に許可するパス |
Sitemap | XMLサイトマップの場所を通知 |
GPTBot等 | 特定AIクローラーを個別にブロック |
生成AIによる学習をブロックしたいときの記述もあわせて、書き方を解説します。
User-agent:対象クローラーを指定
User-agentは、どのクローラーを対象にルールを適用するかを指定するための記述で、必ずrobots.txtの先頭に記述しましょう。
すべてのクローラーを対象にするなら*(ワイルドカード)、特定のクローラーだけ制御したいならGooglebotなどのBot名を指定します。
複数のUser-agentに別々のルールを適用したいときは、ブロックをわけて記述する形です。
User-agent: *
Disallow: /admin/はじめて書くときは、まずUser-agent: *で統一ルールを書くのが鉄則です。
必要に応じ、特定Bot向けのブロックを追加するとミスをふせげます。
Disallow:クロールを拒否
Disallowは、クローラーに訪問してほしくないパスを指定する記述で、robots.txtのなかでもっともよく使う指示です。
Disallow:につづけて拒否したいパスを書くだけのシンプルな記法ですが、書き方で効果範囲が大きく変わります。
| 記述例 | 効果 |
|---|---|
Disallow: / | サイト全体を拒否 |
Disallow: /admin/ | 特定ディレクトリ配下を拒否 |
Disallow: /*.pdf$ | 拡張子指定で拒否 |
Disallow: /?* | パラメータ付きURLを拒否 |
Disallow: | 何も指定しない(=全許可) |
Disallow: /をうっかり本番環境に残すと、全ページがクロール対象から外れ、検索結果から完全消滅してしまうので要注意です。
Allow:Disallow配下で例外的に許可
Allowは、Disallowでブロックしたうちの一部だけをクロールしたいときに使う記述です。
単独で使うケースは少なく、基本的にはDisallowと組み合わせて使います。記述例をみていきましょう。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php上記の例では/wp-admin/というディレクトリをブロックしつつも、配下の/wp-admin/admin-ajax.phpだけ許可しています。
なお、記述ミスでDisallowとAllowに同じディレクトリが指定されているときは、パスが深いほうが優先されるので、Allowが適用される仕様です。
Sitemap:XMLサイトマップの場所を伝える
Sitemapディレクティブは、XMLサイトマップのURLをクローラーに通知する記述で、User-agentとは独立してファイル末尾に書きます。
サイト内の全URLと更新情報をクローラーに伝えるXML形式のファイル。
書き方は「Sitemap: 絶対URL」の1行だけ。複数サイトマップを運用しているときも、改行して並べればすべてGoogleに通知されます。
Sitemap: https://example.com/sitemap.xml
Sitemap: https://example.com/sitemap_news.xmlSitemap記述はルートディレクトリ直下の絶対URLで書くのが鉄則です。
相対パスやファイル名だけの記述では読み取られないケースがあります。サイトマップの位置や名前を変更したときは、必ずSitemap:行も合わせて更新してください。
GPTBot等:AI学習を拒否
AI学習を拒否したいなら、主要AIクローラーを1つずつUser-agentで指定してDisallowします。
AI BotはUser-agent: *だけでは制御できず、Bot名ごとに記述する必要があるからです。
2026年時点で押さえておきたい主要AIクローラーは以下の通りです。
| クローラー名 | 主な用途 |
|---|---|
GPTBot | ChatGPTのモデル学習 |
OAI-SearchBot | ChatGPT Searchの応答生成 |
ChatGPT-User | ChatGPTユーザーの即時取得 |
ClaudeBot | Claudeの学習・応答生成 |
PerplexityBot | Perplexity検索の応答生成 |
Google-Extended | Geminiなどの生成AI学習 |
CCBot | Common Crawl |
主要AIクローラーをすべて拒否するときの記述例は以下です。コピーして自社ドメインのrobots.txtに貼り付ければそのまま使えます。
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /なお、AI検索からの流入はほしいものの、学習には使わせたくないときはGPTBot・Google-Extended・CCBotなどの学習用だけブロックするのもよいでしょう。
福田卓馬robots.txtのようなテクニカル文書はAIとの相性がよく、EXTAGEの「AI文豪」で構成・記述まで一気に効率化できます。
AI文豪なら、SEOのプロが監修するAI記事制作を1記事8,000円から。検索上位獲得率83%の実績で、コストを抑えながら成果の出る記事を量産できます。

\200社以上の支援実績/
robots.txtの正しい配置場所
robots.txtは必ず「サイトのルートディレクトリ直下」に1ファイルだけ設置してください。
https://example.com/blog/robots.txtのように、サブディレクトリに置くとGoogleは認識せず、設定がいっさい効かなくなります。
もうひとつ注意したいのが、サブドメインとプロトコル(HTTPS/HTTP)の扱いです。それぞれ別ファイルとして管理します。
| ドメイン構成 | 必要なrobots.txt |
|---|---|
本体のみ(https://example.comのみ) | 1つ(https://example.com/robots.txt) |
本体+サブドメイン(blog.example.comなど) | 各ドメインに1つずつ(例:example.com/robots.txtとblog.example.com/robots.txt) |
| HTTPSとHTTPが両方稼働中 | 両プロトコルに設置推奨(https://とhttp://双方) |
WordPressでは、初期状態でrobots.txtが生成されるので、編集にはRank Mathなどのプラグインを活用しましょう。
プラグインを使わないなら、FTPでpublic_html/などのサイトルートにrobots.txtを直接アップロードすれば上書きできます。
福田卓馬サーバー設定やCDNの影響で意図と違う内容が返るケースもあるため、本番反映後の目視チェックは必須です。
robots.txtでよくある失敗6選
robots.txtは、代表的な6パターンの失敗を事前に体系化して押さえるだけで、事故発生率を大きく下げられます。逆に、1つでも見落とすと検索順位やアクセスに致命的な影響がでます。
ここでは、EXTAGE株式会社が200社以上のSEO支援現場でみてきたrobots.txtの失敗を6パターンに整理しました。
それぞれくわしく解説します。
パラメータURL無限生成で重要ページが埋もれる
絞り込み検索のパラメータURLが無限に生成されると、クロールバジェットが浪費され、重要ページが評価されなくなります。ECサイト・不動産ポータル・求人サイトで頻発します。
EXTAGE支援先の大手カタログギフトECサイトでは、絞り込みパラメータ起因でインデックス未登録の不要ページが最大29万ページに膨らみ、商品・カテゴリページのクロール頻度が著しく落ちていました。
対策として、パラメータURL全般を拒否しつつ、メインディレクトリだけAllowで許可する方針を採用。次のように記述すると、不要ページは29万から5万まで削減され、主要カテゴリページの検索順位も全体的に上昇しました。
User-agent: *
Disallow: /*?*
Allow: /products/
Allow: /category/クロールやインデックスの仕組みを深く理解したい方は「インデックス数とは?Googleの仕組みと確認方法」でくわしく解説しています。

必要ページをブロックして評価が途切れる
管理系だけブロックしたものの、必要なページまでクロールブロックしてしまうパターンは散見されます。
Disallowは「前方一致」で解釈されるので、書き方を一文字間違えるだけで、公開中の記事まで巻き込んでブロックしてしまいます。
典型的なのは/blog/を拒否するつもりでDisallow: /blogと書いてしまうケース。/blog/配下だけでなく/blog-old/や/blog2024/まで一括ブロックされ、アクセスが激減してしまいます。
# NG例(前方一致で /blog 関連すべてを拒否)
Disallow: /blog# OK例(/blog/ 配下だけ正確にブロック)
Disallow: /blog/preview/拒否したいパスの末尾には、必ず/を付けて範囲を限定しましょう。
テスト用Disallow:/が本番に残る
ステージング環境用のDisallow: /を本番公開時に外し忘れると、公開したばかりのサイトが数週間検索結果にいっさいでてこなくなります。
これからサイトを公開する方、もしくは新しいページを作成中の方は、次のような運用ルールを設けておきましょう。
- 本番公開チェックリストに「
robots.txtのブラウザ目視確認」を必ず入れる - ステージングと本番で
robots.txtファイルをリポジトリ分離する - 本番公開後、URL検査ツールで主要ページのインデックス可否を確認する
リリース当日にrobots.txtファイルを開いてDisallow: /が残っていないか確認するだけで、大事故をふせげます。
noindex併用で逆転現象が起きる
「絶対に検索から外したいから」とrobots.txtでブロックしつつnoindexも付けると、逆にインデックスが残りつづける逆転現象が起きます。
robots.txtでDisallowするとGoogleはそのページにアクセスできず、ページ内のnoindexタグを読み取れません。「二重に安心」のつもりが、検索結果からページが消えない結果を招く典型的な失敗です。
正解は「noindexを効かせたいならクロールは許可し、metaタグだけで制御する」の一択。すでにrobots.txtでブロック済みのページを検索から外したい場合は、以下のSTEPで対処してください。
- 対象ページのHTMLに
<meta name="robots" content="noindex">を追加 robots.txtのDisallow記述を外す- Search ConsoleのURL検査ツールから「インデックス登録をリクエスト」
- 2〜4週間かけてインデックスから除外されるのを待つ
「robots.txtによりブロックされました」エラーへの対処
Search Consoleで「robots.txtによりブロックされました」エラーがでたときは、まず意図したブロックか、事故のブロックかを見わけましょう。
インデックスさせたかったページなら即対処が必要です。意図どおりに拒否しているページ(管理画面・絞り込み結果など)であれば問題なく、対応は不要になります。
事故のブロックの原因は、Disallow記述が広く効きすぎているか、自動生成されたrobots.txtが想定外のパスを拒否しているかのいずれかです。
意図しないブロックだった場合は、次の手順に沿って、原因特定から再クロール依頼まで進めてください。
Search Consoleの対象URLを開き、どのDisallow行でブロックされているかエラー詳細を確認します。(所要3分)
自社サイトのrobots.txtをブラウザで開き、該当URLをブロックしているDisallowを特定します。(所要3〜5分)
特定したDisallow行を削除するか、前方一致で広く効きすぎているときは末尾に/をつけて範囲を限定します。(所要5分)
修正後のrobots.txtをFTPやCMSの管理画面からサーバーのルートディレクトリにアップロードします。(所要5分)
Googleサーチコンソール「robots.txt」レポートから、Googleに最新版の再読み込みをリクエストします。(所要1分)
URL検査ツールで該当URLを検査し、「インデックス登録をリクエスト」ボタンから再クロールを依頼します。(所要3分)
CMS自動生成を放置して重要部がブロック
CMSが自動生成するrobots.txtファイルを確認しないまま運用し、プラグインや初期設定が重要ディレクトリまでブロックしているケースがあとを絶ちません。
WordPressでは、画像・CSS・JSがwp-content/の配下に置かれます。ブロックしてしまうとコンテンツに必要なリソースを取得できず、見た目が崩れるリスクがあります。
WordPressでサイトを運営しているなら、サイト公開時・リニューアル時・プラグイン追加時の3タイミングで必ずrobots.txtファイルをチェックしましょう。思うように検索順位が付かない・順位変動がおかしい場合も同様です。
robots.txt以外にも「なぜかGoogleクローラーが来ない」という悩みがある方は「Googleクローラーが来ない原因と対処法|SEO支援200社以上の知見で解説」で原因分類からくわしく解説しています。

robots.txtに関するよくある質問
robots.txtテスターは廃止された?
はい、旧robots.txtテスターは2023年12月に廃止されました。
現在はGoogleサーチコンソールではなく「Validator」や「robots.txt許可チェッカー」といった無料ツールを活用しましょう。
設定が反映されるまでどのくらいかかる?
robots.txtの変更は、早ければ数時間〜数日以内にGoogleに反映されます。Googleは通常24時間ごとにrobots.txtを再取得しますが、急ぎたいときはSearch Consoleのrobots.txtレポートから再読み込みをリクエスト可能です。
ただし、一度インデックスされたページをrobots.txtでブロックしても検索結果から消えるまでには数週間〜数ヵ月かかるので、すぐ消したいならnoindexを使うのが適切です。
被リンクやページランクに影響する?
robots.txtでブロックしたページも、外部からの被リンクを受けること自体は可能です。ただし、Googleはそのページの中身をクロールできないので、リンク評価の伝達は限定的になってしまいます。
被リンク経由の評価を最大化したいページは、robots.txtで拒否せず、必要ならnoindex,followで検索結果だけ除外する運用を検討してください。
第三者にrobots.txtを見られて問題ない?
robots.txtは、誰でも閲覧できる公開ファイルです。とくに「/admin/」や「/staging/」などのパスをDisallowで記述すると、スパム業者などに存在するディレクトリを教えることになります。
パス自体を知られたくないような管理領域は、robots.txtに記述せず、Basic認証やIPアドレス制限でアクセス遮断するのが理想です。
robots.txtは一度書いて終わりではありません。サイトの更新やリニューアルのたびに、点検する運用を組み込んでください。
ここまでの内容を早見表にまとめておきます。
| 項目 | 結論 |
|---|---|
| 役割 | クローラーに「クロール可否」を伝えるテキストファイル。検索結果の除外ではなくクロール制御用。 |
| 配置場所 | サイトのルートディレクトリ直下に1ファイルのみ。サブドメイン・プロトコルごとに別ファイルで管理。 |
| 確認方法 | 目視・Search Consoleレポート・URL検査・外部Validatorの4つを用途別に使い分ける。 |
| 基本ディレクティブ | User-agent/Disallow/Allow/Sitemapの4つ。AI学習拒否はBot名ごとに個別指定。 |
| 最大の事故原因 | Disallow: /の本番残り、前方一致の書き間違い、noindexとの併用による逆転現象。 |
| 設定前の必須作業 | 自社サイトのディレクトリ構造を把握し、許可/拒否するパスをリストアップする。 |
| 点検タイミング | サイト公開時・リニューアル時・プラグイン追加時の3タイミングで必ず確認する。 |
福田卓馬クロール制御を含めたサイト全体の設計を体系的に整理できる無料マニュアルを配布中です。

オウンドメディアのサイト設計手順をまとめた、30ページ超えの教科書コンテンツを無料配布中。ターゲット分析からキーワードの決め方、売上につながる導線設計まで完全網羅しているので、ぜひ無料で受け取って活用してみてください。